Indexierungsstatus prüfen: So sehen Sie sofort, ob Google Ihre Seiten kennt
Joel Heuchert
SEO Experte
Was ist der Indexierungsstatus?
Der Indexierungsstatus einer Seite beschreibt, ob Google diese URL kennt, gespeichert hat und für Suchanfragen berücksichtigt. Vereinfacht gesagt: Ist eine Seite nicht im Google-Index, existiert sie für Suchende schlicht nicht. Sie können noch so guten Inhalt veröffentlichen, noch so viele Backlinks aufbauen, wenn Google die Seite nicht indexiert hat, erscheint sie in keiner Suchergebnisliste.
Das klingt nach einem technischen Detail am Rande. In der Praxis ist es aber einer der häufigsten Gründe, warum Seiten keinen organischen Traffic bekommen. Wir sehen das regelmäßig in Audits: Unternehmenswebsites mit Dutzenden oder hunderten von Seiten, von denen ein erheblicher Anteil nie indexiert wurde, weil technische Einstellungen, Crawl-Barrieren oder fehlerhafte Weiterleitungen den Googlebot blockiert haben.
Die Google Indexierung ist kein einmaliger Vorgang. Google crawlt Websites kontinuierlich und aktualisiert den Index laufend. Neue Seiten werden aufgenommen, veränderte Inhalte neu bewertet, und Seiten, die dauerhaft Fehler liefern oder technisch blockiert sind, werden aus dem Index entfernt. Der Indexierungsstatus ist damit kein statischer Wert, sondern ein lebendiges Signal.
Indexierungsstatus prüfen: drei Methoden im Überblick
Es gibt mehrere Wege, um zu prüfen, wie es um den Indexierungsstatus Ihrer Seiten steht. Jede Methode hat andere Stärken.
Methode 1: Der site:-Befehl in der Google-Suche
Der schnellste erste Check ist der site:-Operator direkt in der Google-Suche. Sie geben einfach site:ihredomain.de in die Suchleiste ein und erhalten eine Liste aller URLs, die Google aktuell im Index führt.
Diese Methode hat ihre Grenzen. Google zeigt hier keine exakten Zahlen, die Ergebnisse sind nicht vollständig und geben keinen Aufschluss über den Status einzelner Unterseiten. Für einen groben Überblick oder die Kontrolle einer einzelnen URL eignet sie sich trotzdem, vor allem wenn Sie keinen Zugang zur Search Console haben.
Für eine einzelne URL geben Sie ein: site:ihredomain.de/ihre-seite. Erscheint die Seite in den Ergebnissen, ist sie indexiert. Erscheint sie nicht, heißt das nicht zwingend, dass sie ausgeschlossen ist, aber es ist ein erster Hinweis.
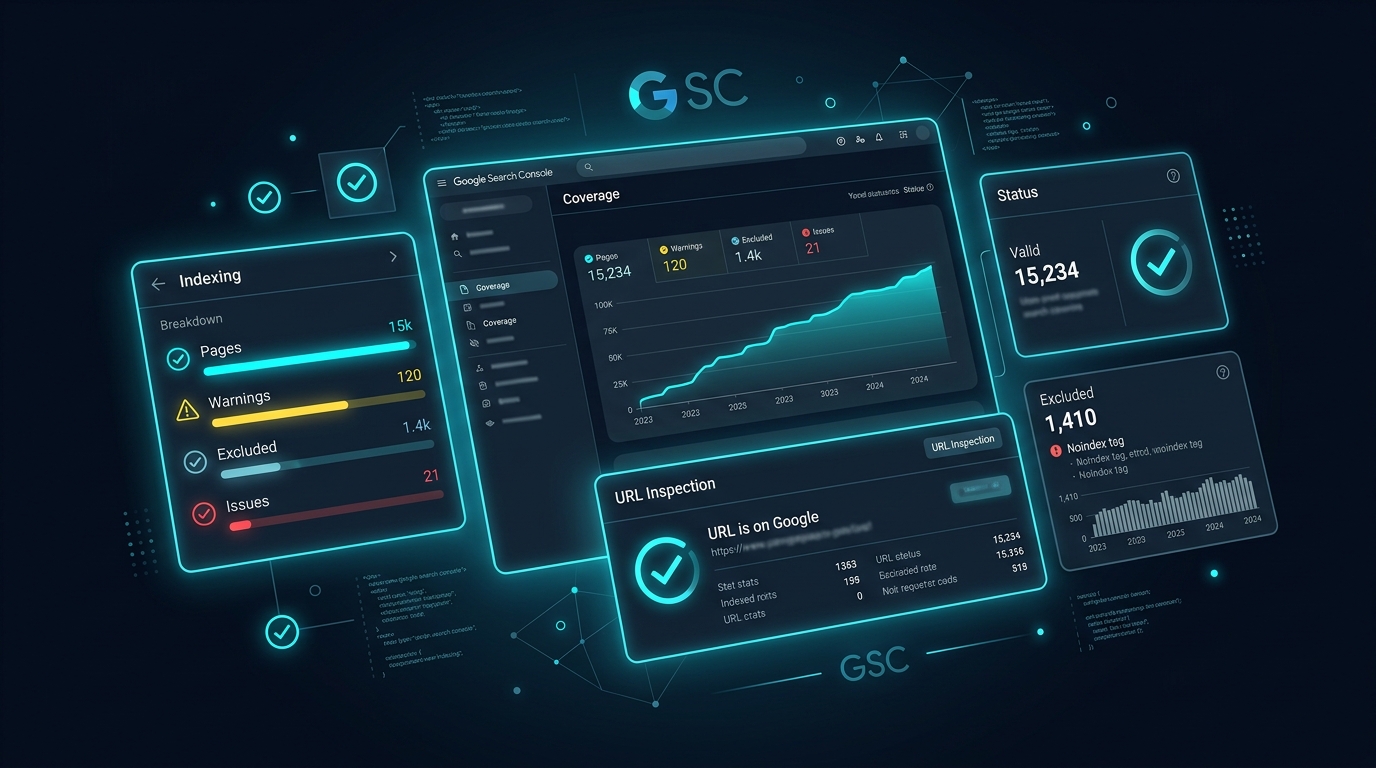
Methode 2: URL-Prüfung in der Google Search Console
Die genaueste Methode für einzelne URLs ist die URL-Prüfung in der Google Search Console. Sie geben die gewünschte URL oben in der Suchleiste der Console ein und erhalten innerhalb weniger Sekunden einen detaillierten Bericht: Ist die Seite indexiert? Wann hat Google sie zuletzt gecrawlt? Welche kanonische URL hat Google festgestellt? Gibt es Crawling-Probleme?
Dieser Bericht gibt außerdem Auskunft darüber, wie die Seite gerendert wurde. Das ist besonders relevant für JavaScript-lastige Seiten, bei denen der Googlebot unter Umständen nicht den vollständigen Inhalt sieht, den ein menschlicher Nutzer sieht.
Methode 3: Der Coverage-Bericht in der Search Console
Für eine seitenübergreifende Analyse ist der Coverage-Bericht (Abdeckungsbericht) das wichtigste Werkzeug. Sie finden ihn in der Search Console unter "Indexierung" und dann "Seiten". Hier sehen Sie auf einen Blick, wie viele Seiten Ihrer Website indexiert sind, wie viele ausgeschlossen wurden und warum.
Der Bericht unterteilt sich in vier Kategorien: Fehler, Gültig mit Warnung, Gültig und Ausgeschlossen. Jede Kategorie lässt sich aufklappen, um die konkreten URLs und die jeweiligen Gründe einzusehen. Für ein erstes Verständnis der Indexierungslage Ihrer Website ist dieser Bericht unverzichtbar.
Status-Typen: Was bedeuten die Einträge?
Die Search Console unterscheidet zwischen mehreren Status-Typen. Welche davon ein Problem darstellen und welche normal sind, ist für viele Websitebetreiber nicht sofort klar.
| Status-Typ | Bedeutung | Handlungsbedarf |
|---|---|---|
| Indexiert | Google hat die Seite gecrawlt und in den Index aufgenommen. Sie kann in Suchergebnissen erscheinen. | Keiner, solange die Seite ranken soll |
| Nicht indexiert: Noindex-Tag | Ein noindex-Meta-Tag oder HTTP-Header weist Google an, die Seite aus dem Index auszuschließen. | Prüfen, ob das noindex-Tag bewusst gesetzt wurde. Falls nicht, sofort entfernen. |
| Nicht indexiert: Crawl-Anomalie | Google konnte die Seite nicht abrufen, zum Beispiel wegen eines Serverfehlers oder Timeouts. | Serverprobleme und Erreichbarkeit prüfen |
| Ausgeschlossen: Weitergeleitet | Die URL wurde per 301 oder 302 auf eine andere URL weitergeleitet. Google indexiert das Weiterleitungsziel, nicht die Quelle. | Prüfen, ob das Ziel korrekt indexiert ist |
| Ausgeschlossen: Kanonische URL von Google ausgewählt | Google hat eine andere URL als kanonisch eingestuft, nicht die von Ihnen angegebene. | Canonical-Tags überprüfen und Duplicate Content analysieren |
| Ausgeschlossen: Durch robots.txt blockiert | Die Seite ist in der robots.txt-Datei für Googlebot gesperrt. | Prüfen, ob die Sperre gewollt ist. Falls nicht, robots.txt anpassen. |
| Ausgeschlossen: Gefunden, aber nicht indexiert | Google kennt die Seite, hat sie aber noch nicht gecrawlt oder bewusst nicht indexiert. Oft ein Qualitätssignal. | Inhalt der Seite überprüfen, ggf. verbessern oder löschen |
| Fehler: Seite nicht gefunden (404) | Die URL liefert einen 404-Statuscode. Die Seite existiert nicht (mehr). | Weiterleitung einrichten oder Seite wiederherstellen, wenn der Inhalt wertvoll war |
Wann sollten Sie sich Sorgen machen?
Nicht jede ausgeschlossene Seite ist ein Problem. Paginierungsseiten, interne Suchtreffer-Seiten, Danke-Seiten nach Formularabsendungen oder Login-Bereiche sollten bewusst aus dem Index ausgeschlossen sein. Das ist gewollt und richtig so.
Kritisch wird es in diesen Situationen:
- Wichtige Landingpages sind nicht indexiert. Ihre Leistungsseite, Produktkategorie oder Hauptblogbeiträge tauchen im Coverage-Bericht unter "Nicht indexiert" auf. Das bedeutet: Kein organischer Traffic für genau die Seiten, die Traffic bringen sollten.
- Der Anteil ausgeschlossener Seiten steigt ohne erkennbaren Grund. Wenn von einem Monat auf den anderen deutlich mehr Seiten aus dem Index fallen, ist etwas schiefgelaufen. Das kann ein fehlerhaftes Deployment, ein falsch gesetztes noindex-Tag oder eine robots.txt-Änderung sein.
- Google wählt eine andere kanonische URL als Sie. Das deutet auf Duplicate-Content-Probleme hin, also auf mehrere URLs mit identischem oder sehr ähnlichem Inhalt. Google entscheidet dann selbst, welche Version es indexiert.
- Seiten mit guten Backlinks sind nicht indexiert. Backlinks helfen, aber wenn Google die Zielseite nicht indexiert, verpufft der Linkwert.
Besonders tückisch ist der Status "Gefunden, aber nicht indexiert". Google kennt die URL, hat aber entschieden, sie vorerst nicht in den Index aufzunehmen. Oft ist das ein Hinweis auf dünnen Inhalt, zu viele ähnliche Seiten oder schlechte Core Web Vitals, die das Crawl-Budget belasten. Solche Seiten brauchen keine technische Korrektur, sondern eine inhaltliche Aufwertung.
Häufige Ursachen für Indexierungsprobleme
Die Gründe, warum Seiten nicht oder falsch indexiert werden, sind vielfältig. In der Praxis sehen wir immer wieder dieselben Muster.
noindex-Tags aus Versehen gesetzt
Das passiert häufiger als man denkt. Während der Entwicklung wird eine Seite mit noindex geschützt, damit Google keine unfertige Version indexiert. Nach dem Launch vergisst jemand, das Tag zu entfernen. Die Seite geht live, aber Google indexiert sie nicht. Wir empfehlen, jeden Deployment-Prozess um eine explizite Prüfung auf ungewollte noindex-Tags zu ergänzen.
robots.txt blockiert wichtige Bereiche
Eine falsch konfigurierte robots.txt kann ganze Verzeichnisse für den Googlebot sperren. Besonders bei WordPress-Seiten kommt es vor, dass Plugins oder Theme-Updates die robots.txt unbemerkt verändern. Ein regelmäßiger Check gehört zur technischen Grundhygiene.
Canonical-Fehler
Wenn mehrere URLs denselben Inhalt ausliefern, ohne dass ein Canonical-Tag auf die bevorzugte Version verweist, muss Google selbst entscheiden. Diese Entscheidung fällt nicht immer so aus, wie Sie es sich vorstellen.
Crawl-Budget-Probleme bei großen Websites
Für große Websites mit tausenden Seiten ist das Crawl-Budget relevant. Google besucht nicht alle Seiten unbegrenzt oft. Wenn ein Teil des Budgets für irrelevante URLs verbraucht wird, etwa endlose Filterkombinationen in einem Onlineshop, bleiben wichtige Seiten unter Umständen unbesucht.
Indexierungsstatus verbessern: konkrete Maßnahmen
Wenn Sie Indexierungsprobleme identifiziert haben, gibt es klare Schritte, um sie zu beheben. Für einen strukturierten Überblick empfehlen wir, zuerst einen SEO-Audit durchzuführen, um alle technischen Baustellen auf einmal zu erfassen und zu priorisieren.
- Ungewollte noindex-Tags entfernen. Durchsuchen Sie Ihren Quellcode und Ihr CMS systematisch nach noindex-Einträgen.
- robots.txt überprüfen. Nutzen Sie das robots.txt-Testingtool in der Search Console, um zu sehen, welche URLs geblockt sind.
- XML-Sitemap einreichen. Eine aktuelle, korrekte Sitemap hilft Google, alle relevanten URLs zu finden und zu priorisieren.
- Thin Content konsolidieren. Seiten mit sehr wenig Inhalt zusammenfassen, auf eine Hauptversion weiterleiten und die Canonical-Tags korrekt setzen.
- URL-Indexierung beantragen. Für einzelne wichtige URLs können Sie in der Search Console direkt eine erneute Indexierung beantragen.
Komplexere Fälle behandeln wir detailliert in unserem Artikel über Indexierungsprobleme beheben.
Wie oft sollten Sie den Indexierungsstatus prüfen?
Für kleinere Websites reicht ein monatlicher Check des Coverage-Berichts in der Search Console. Für Shops, News-Seiten oder Websites, die regelmäßig neue Inhalte veröffentlichen, empfehlen wir einen wöchentlichen Blick, mindestens auf die Fehlerkategorie.
Nach jedem größeren technischen Update, also nach Relaunches, CMS-Wechseln, Theme-Updates oder umfangreichen Umstrukturierungen, sollte die Indexierungssituation sofort geprüft werden. Solche Eingriffe sind die häufigste Ursache für plötzliche Indexierungsverluste.
Für Unternehmen, die organischen Traffic als wichtigen Kanal behandeln, gehört das Monitoring des Indexierungsstatus in das regelmäßige Reporting. Ein Problem, das früh erkannt wird, verursacht deutlich weniger Schaden als eines, das Wochen unentdeckt bleibt.